
Everything in AI Alignment starts here, because nothing else is possible until it’s true: a model can’t mention a brand it can’t find. Discoverability is the foundation layer — being present, crawlable, and readable in the places AI looks before it writes an answer.
Most “we’re invisible in ChatGPT” problems are, at root, discoverability problems. Before you spend a cent on clever content, it’s worth understanding how a model finds anything at all.
How AI actually finds things
There’s a myth worth killing first: that AI answers come purely from what the model “memorised” during training. Sometimes they do. But increasingly, modern AI search retrieves before it answers — a pattern researchers call retrieval-augmented generation, or RAG1.
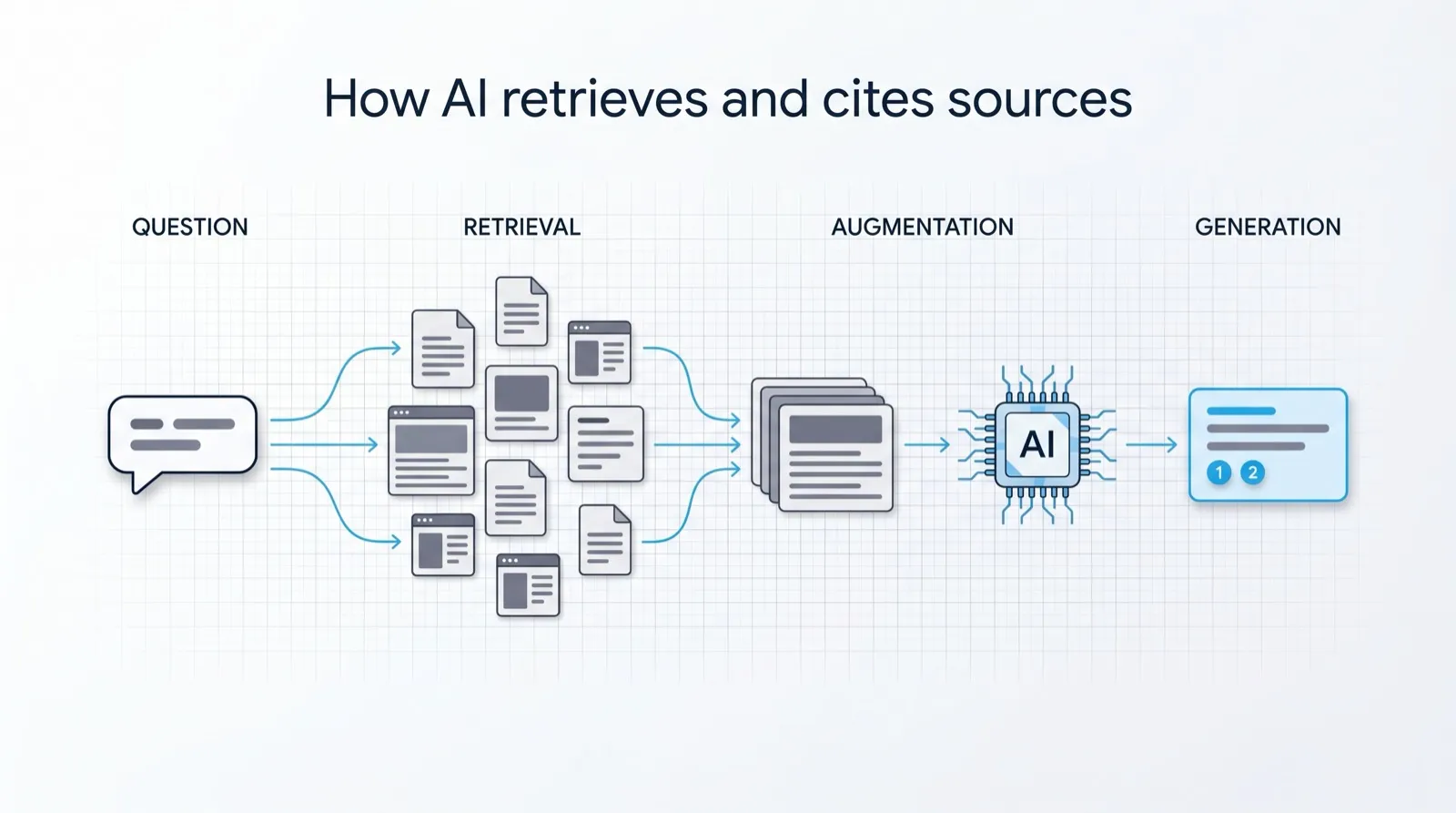
In plain terms, three things happen when a buyer asks a question:
- Retrieval. The system interprets the question and fetches relevant content — from a live web search, an index, and the model’s training data.
- Augmentation. It assembles the best of what it found into context for the model.
- Generation. The model writes an answer grounded in that retrieved material — and, on tools like Perplexity and AI Overviews, cites it.
This is great news, because it means discoverability is winnable. You don’t have to wait for the next training run to be “remembered.” If your brand is present in the sources a model retrieves at answer-time, you can show up today. If it isn’t, you won’t — no matter how good your product is.
So discoverability has two halves: can AI read your own site, and is your brand present in the third-party sources AI trusts.
Half one: can AI read your site?
If AI crawlers can’t fetch your pages, you’ve opted out of the retrieved web. This breaks in a few common, fixable ways.
You’re blocking AI bots — maybe by accident. AI companies crawl with named user agents: OpenAI uses GPTBot and OAI-SearchBot, Anthropic ClaudeBot, Perplexity PerplexityBot, Google Google-Extended, and so on. Many sites block some of these in robots.txt — sometimes deliberately, often via a plugin or default someone enabled and forgot. Worse, infrastructure can block them for you: Cloudflare began blocking AI crawlers by default, which means a brand can be invisible to AI without anyone on the team ever making that choice. Check it.
Your content is locked behind JavaScript or logins. If the substance of a page only appears after heavy client-side rendering, or sits behind a gate, retrieval often misses it. The facts that matter about you should be in plain, server-rendered HTML.
Your important facts aren’t on crawlable pages at all. Pricing trapped in an image, product details only inside a PDF or a video, key claims living solely on a third-party platform — all of it is hard to retrieve.
A quick self-check from the command line tells you whether a bot can even fetch your homepage:
curl -A "GPTBot" -I https://yourdomain.com/
curl -A "GPTBot" https://yourdomain.com/robots.txtIf you get a 403, a redirect to a challenge page, or a Disallow covering the bot, that’s your first fix — and it’s usually a same-day one.
Make yourself easy to parse. Beyond “not blocked,” you want “easy to read.” Clean HTML, real headings, descriptive link text, and increasingly an llms.txt file — a simple, plain-language map of your most important content for AI consumers. It’s an emerging convention, not a magic switch, but it’s low-cost and signals the right things.
Half two: be present in the sources AI trusts
Here’s the part that surprises traditional SEOs: your own website is not the main event. When Ahrefs studied 75,000 brands, the factors most correlated with AI visibility were about presence across the web — brand web mentions, mentions on YouTube, brand search demand — far more than on-site metrics like Domain Rating or page count. As they put it, AI visibility isn’t just about your website; it’s about how widely your brand shows up2.
And models lean heavily on a predictable set of third-party sources. Across tens of millions of AI citations, the most-cited domains skew toward Reddit, YouTube, Wikipedia, and LinkedIn3, with review sites like G2 and Yelp showing up heavily on recommendation queries. The exact mix varies by platform and shifts over time — but the lesson is stable: the answer about you is often assembled from places you don’t own.
That means discoverability work includes:
- Being on the platforms models cite. A real presence (not a ghost profile) on the review sites, communities, and directories relevant to your category.
- Being in the comparison content. “Best X” listicles, roundups, and alternatives pages — the raw material for category and comparison answers.
- Being talked about, not just present. A mention in a discussion thread or an industry article is a retrievable signal; a static profile nobody links to barely is.
This is the bridge to the Authority layer, where we go deep on earning those mentions. Discoverability is making sure you’re present and readable; authority is making sure you’re present enough, in credible enough places, to get chosen.
Your Discoverability checklist
Work top to bottom — the cheap technical fixes first, then the ongoing presence work.
- AI crawlers (
GPTBot,OAI-SearchBot,ClaudeBot,PerplexityBot,Google-Extended) are allowed inrobots.txt. - No infrastructure-level block (Cloudflare / WAF / bot manager) is silently stopping AI bots.
- Core facts (what you do, pricing, key features) are in server-rendered HTML, not images, PDFs, or JS-only.
- Clean semantic structure: real
<h1>/<h2>s, descriptive link text, sensible page titles. - An
llms.txt(and a currentsitemap.xml) is published. - You have a genuine, accurate presence on the review sites, communities, and directories for your category.
- You appear in at least some “best [category]” and “[competitor] alternatives” content.
- You know which domains AI cites for your category (from your audit) and you’re present on them.
Further reading: 4
Sources
-
Search Engine Land — AI search engines cite Reddit, YouTube, and LinkedIn most (study) ↩